BERT – Transfer Learning
Bi-directional Encoder Representations from Transformers, or BERT is a language representation model developed by Google Research in May 2019 which formed the basis for significant improvement in natural language processing. It uses two steps pre-training and fine-training, to create state of the art models for a wide range of tasks which means that the same pre-trained model can we fine tuned for various tasks to give state of the art results.
Some of the common applications of BERT are-
- Text summarization
- Sentiment Analysis
- Text Prediction etc.
BERT is based on two foundational advancements encoder-decoder network architecture and Attention Mechanism. The attention mechanism further evolved to produce transformer architecture which is the building block of BERT.
Encoder-Decoder Networks –
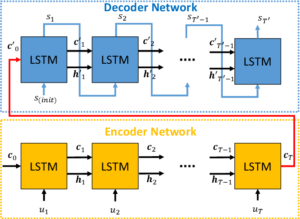
We have frequently seen use of LSTM and BiLSTM on sentences modelled as sequence of words. These sentences are generally of variable length, for every input for LSTM it generates output. The number of outputs depend upon the number of inputs which results in a problem as the model fails to handle sentences for variable length in input and output. To overcome this problem the encoder-decoder network was designed. Encoder that processes the input and encoder is composed of multiple LSTM/BiLSTM whose output is collected by End-Of-Sentence Token. This vector which is a collection of output from each unit becomes the input for Decoder. Each unit in decoder generates an output which is collected for EOS unit resulting in an output which can be of different length as compared to input with its on characteristics.
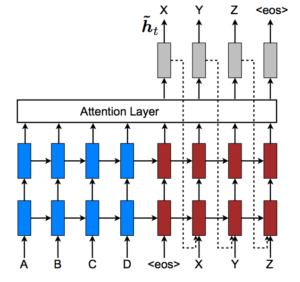
Attention Model –
In the encoder-decoder model the encoder part of the network created a fixed representation of the in input sequence in dimension space. As the length of the input grew, it would be compressed into this vector. The encodings or hidden states generated are visible to the decoder layer. The attention mechanism allows the decoder part of the network to see the encoder hidden states. These input token encodings are made available to the decoder, this is known as General attention and it refers to the ability of the output token to have direct access to the dependences in the encodings and hidden states of the inputs provided which helps decoder as it operates on a sequence of vectors generated by encoding the input rather than one fixed vector generated at the end of input.
Two Major changes are as follows –
- The encoder layer uses BiLSTM as it allows to learn from the preceding and succeeding words which helps the model to consider whole sentence. In encoder-decoder LSTM were being used.
- Decoder is able to access the encodings and hidden states of the encoder rather than just EOS token.
The hidden state output of each input token is multiplied by an alignment weight that represents the degree of match between the input token at a specific position with the output token in question. A context vector is computed by multiplying each input hidden state output with the corresponding alignment weight and concatenating all the results. This context vector is fed to the output token along with the previous output token.
BERT model –
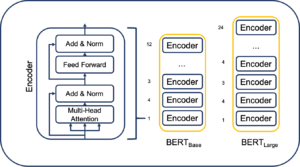
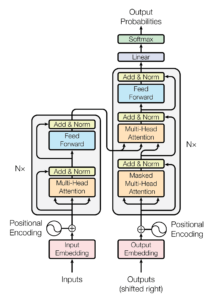
It only uses the encoder part of the model. An encoder block of the transformer architecture has multiple sub-parts – the multi-head self-attention sub-layer and a feed-forward sub-layer. The self-attention sub-layer works on all the tokens of the input sentence and generates an encoding for each word in context of each other. The feed-forward sublayer is composed of two layers using linear transformations and a ReLU activation in between. Each encoder block is composed of these two sub-layers, while the entire encoder is composed of six such blocks. BERT contains 12 encoder blocks with 12 attention heads.
Multi-head attention block and feed-forward block is joined with a residual connection. While adding the output of the sublayer with the input it received, layer normalization is performed. The main innovation here is the Multi-Head Attention block. There are eight identical attention blocks whose outputs are concatenated to produce the multi-head attention output. Each attention block takes in the encoding and defines three new vectors called the query, key, and value vectors. Each of these vectors is defined as 64-dimensional, though this size is a hyperparameter that can be tuned. The query, key, and value vectors are learned through training.
Multi-head self-attention creates multiple copies of the query, key, and value vectors along with the weights matrix used to compute the query from the embedding of the input token. The paper proposed eight heads, though this could be experimented with. An additional weight matrix is used to combine the multiple outputs of each of the heads and concatenate them together into one output value vector. This output value vector is fed to the feed-forward layer, and the output of the feed-forward layer goes to the next encoder block or becomes the output of the model at the final encoder block.